Preface
SQL optimization is a hot topic that everyone is concerned about. Whether you are in an interview or at work, you are likely to encounter it.
If there is a performance problem on an online interface you are responsible for one day, you need to optimize it. Then your first thought is probably to optimize the sql statement, because its transformation cost is much smaller than the code.
So, how to optimize the sql statement?
This article shares some tips for sql optimization from 15 aspects, hoping to help you.
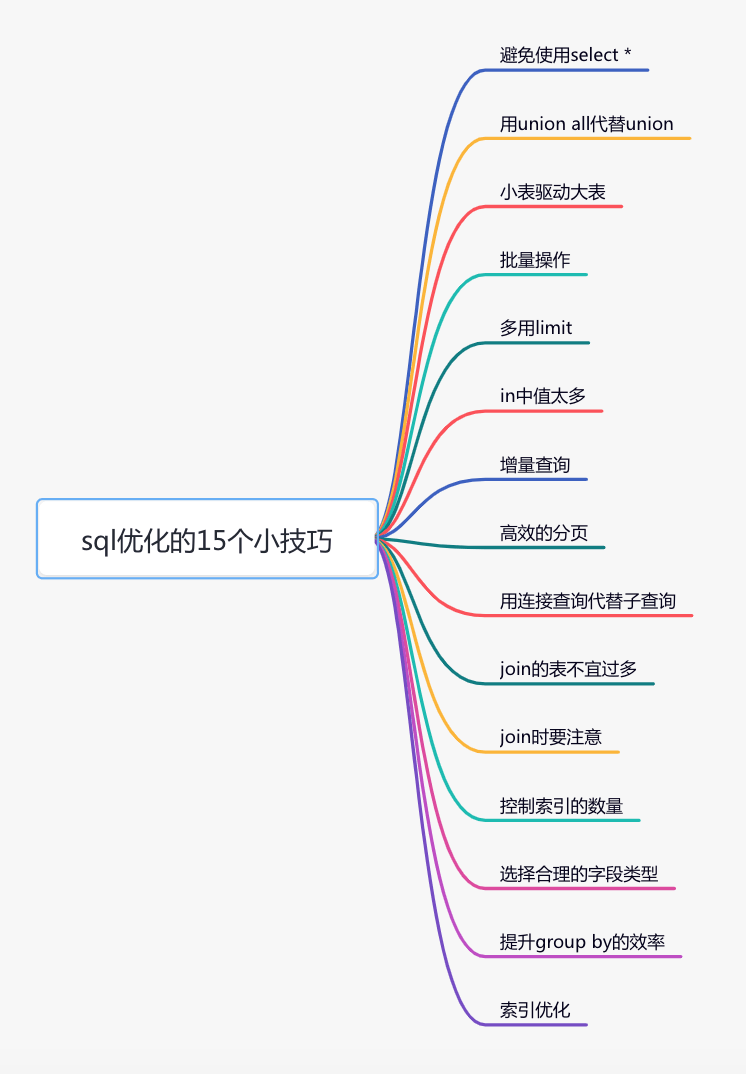
15 SQL Optimization Tips
1. Avoid using select *
Many times, when we write SQL statements, for convenience, we like to use select * directly to find out the data of all columns in the table at one time.
Counter example:
select * from user where id=1;In actual business scenarios, maybe we only really need to use one or two of these columns. I checked a lot of data, but no, it wasted database resources, such as memory or cpu.
In addition, during the process of data transmission through network IO, the data transmission time will also be increased.
There is another most important problem: select * will not use covering index, there will be a large number of return table operations, resulting in low performance of query sql.
So, how to optimize it?
Positive example:
select name,age from user where id=1;When querying sql statements, only the columns that need to be used are checked, and the redundant columns do not need to be checked out at all.
2. Replace union with union all
We all know that after using the union keyword in the SQL statement, you can get the data after sorting.
And if you use the union all keyword, you can get all data, including duplicate data.
Counter example:
(select * from user where id=1)
union
(select * from user where id=2);The process of reordering requires traversal, sorting and comparison, which is more time-consuming and consumes more CPU resources.
So if you can use union all, try not to use union.
Positive example:
(select * from user where id=1)
union all
(select * from user where id=2);Unless there are some special scenarios, such as after union all, duplicate data appears in the result set, and duplicate data is not allowed in business scenarios, then union can be used.
3. Small tables drive large tables
A small table drives a large table, that is, a data set of a small table drives a data set of a large table.
If there are two tables, order and user, the order table has 10,000 pieces of data, and the user table has 100 pieces of data.
At this time, if you want to check the list of orders placed by all valid users.
This can be achieved using the in keyword:
select * from order
where user_id in (select id from user where status=1)This can also be achieved using the exists keyword
select * from order
where exists (select 1 from user where order.user_id = user.id and status=1)In the business scenario mentioned above, it is more appropriate to use the in keyword to achieve business requirements.
why?
Because if the in keyword is included in the sql statement, it will execute the subquery statement in in first, and then execute the statement outside in. If the amount of data in in is small, the query speed is faster as a condition.
And if the sql statement contains the exists keyword, it executes the statement to the left of exists first (ie the main query statement). Then use it as a condition to match the statement on the right. If it matches, you can query the data. If there is no match, the data is filtered out.
In this requirement, the order table has 10,000 pieces of data, and the user table has 100 pieces of data. The order table is a large table, and the user table is a small table. If the order table is on the left, it is better to use the in keyword.
in conclusion:
- in applies to the large table on the left and the small table on the right
existsapplies to the small table on the left and the large table on the right.
Whether you use the in or exists keyword, the core idea is to use a small table to drive a large table.
4. Batch operations
What if you have a batch of data that needs to be inserted after business processing?
Counter example:
for(Order order: list){
orderMapper.insert(order):
}Insert data one by one in a loop.
insert into order(id,code,user_id)
values(123,'001',100);This operation requires multiple requests to the database to complete the insertion of this batch of data.
But as we all know, in our code, every time we request the database remotely, it will consume a certain amount of performance. And if our code needs to request the database multiple times to complete this business function, it will inevitably consume more performance.
So how to optimize it?
Positive example:
orderMapper.insertBatch(list):Provides a method to insert data in batches.
insert into order(id,code,user_id)
values(123,'001',100),(124,'002',100),(125,'003',101);In this way, you only need to request the database remotely once, and the SQL performance will be improved. The more data, the greater the improvement.
However, it should be noted that it is not recommended to operate too much data in batches at one time. If there is too much data, the database response will be very slow. Batch operations need to grasp a degree, and it is recommended that each batch of data be controlled within 500 as much as possible. If the data is more than 500, it will be processed in multiple batches.
5. Use limit
Sometimes, we need to query the first item in some data, for example: query the first order placed by a user, and want to see the time of his first order.
Counter example:
select id, create_date
from order
where user_id=123
order by create_date asc;Query orders according to the user id, sort by order time, first find out all the order data of the user, and get an order set. Then in the code, get the data of the first element, that is, the data of the first order, to get the time of the first order.
List<Order> list = orderMapper.getOrderList();
Order order = list.get(0);Although this approach has no problem in function, it is very inefficient. It needs to query all the data first, which is a bit of a waste of resources.
So, how to optimize it?
Positive example:
select id, create_date
from order
where user_id=123
order by create_date asc
limit 1;Use limit 1 to return only the data with the smallest order time of the user.
In addition, when deleting or modifying data, in order to prevent misoperation, resulting in deletion or modification of irrelevant data, limit can also be added at the end of the sql statement.
E.g:
update order set status=0,edit_time=now(3)
where id>=100 and id<200 limit 100;In this way, even if the wrong operation, such as the id is wrong, it will not affect too much data.
6. Too many median values in in
For bulk query interfaces, we usually use the in keyword to filter out data. For example: I want to query user information in batches through some specified ids.
The sql statement is as follows:
select id,name from category
where id in (1,2,3...100000000);If we do not impose any restrictions, the query statement may query a lot of data at one time, which may easily cause the interface to time out.
What should we do then?
select id,name from category
where id in (1,2,3...100)
limit 500;You can limit the data with limit in sql.
However, we are more about adding restrictions to the business code. The pseudo code is as follows:
public List<Category> getCategory(List<Long> ids) {
if(CollectionUtils.isEmpty(ids)) {
return null;
}
if(ids.size() > 500) {
throw new BusinessException("A maximum of 500 records can be queried at a time")
}
return mapper.getCategoryList(ids);
}Another solution is: if there are more than 500 records in ids, you can use multiple threads to query the data in batches. Only 500 records are checked in each batch, and finally the queried data are aggregated and returned.
However, this is only a temporary solution and is not suitable for scenes with too many ids. Because there are too many ids, even if the data can be quickly detected, if the amount of data returned is too large, the network transmission will consume a lot of performance, and the interface performance will not be much better.
7. Incremental query
Sometimes, we need to query data through a remote interface and then synchronize to another database.
Counter example:
select * from user;If you get all the data directly, then sync it. Although this is very convenient, it brings a very big problem, that is, if there is a lot of data, the query performance will be very poor.
What should we do then?
Positive example:
select * from user
where id>#{lastId} and create_time >= #{lastCreateTime}
limit 100;In ascending order of id and time, only one batch of data is synchronized each time, and this batch of data has only 100 records. After each synchronization is completed, save the largest id and time of the 100 pieces of data for use when synchronizing the next batch of data.
This incremental query method can improve the efficiency of a single query.
8. Efficient paging
Sometimes, when querying data on the list page, in order to avoid returning too much data at one time and affecting the performance of the interface, we generally paginate the query interface.
The limit keyword commonly used for paging in mysql:
select id,name,age
from user limit 10,20;If the amount of data in the table is small, using the limit keyword for paging is no problem. But if there is a lot of data in the table, there will be performance problems with it.
For example, the pagination parameter now becomes:
select id,name,age
from user limit 1000000,20;MySQL will find 1,000,020 pieces of data, then discard the first 1,000,000 pieces of data, and only check the last 20 pieces of data, which is a waste of resources.
So, how to paginate this massive data?
Optimize sql:
select id,name,age
from user where id > 1000000 limit 20;First find the largest id of the last paging, and then use the index on the id to query. However, in this scheme, the id is required to be continuous and ordered.
You can also use between to optimize pagination.
select id,name,age
from user where id between 1000000 and 1000020;It should be noted that between should be paginated on the unique index, otherwise there will be an inconsistent size of each page.
9. Replacing subqueries with join queries
If you need to query data from more than two tables in mysql, there are generally two implementation methods:
Subqueries and Join Queries.
An example of a subquery is as follows:
select * from order
where user_id in (select id fromuser where status=1)Subqueries can be implemented through the in keyword, and the conditions of one query statement fall within the query results of another select statement. The program runs on the nested innermost statement first, and then runs the outer statement.
The advantage of a subquery statement is that it is simple and structured, if the number of tables involved is small.
But the disadvantage is that when mysql executes sub-queries, temporary tables need to be created. After the query is completed, these temporary tables need to be deleted, which has some additional performance consumption.
At this time, it can be changed to a connection query. Specific examples are as follows:
select o.* from order o
inner join user u on o.user_id = u.id
where u.status=110. The join table should not be too many
According to the Alibaba developer manual, the number of join tables should not exceed 3
Counter example:
select a.name,b.name.c.name,d.name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id
inner join d on d.c_id = c.id
inner join e on e.d_id = d.id
inner join f on f.e_id = e.id
inner join g on g.f_id = f.idIf there are too many joins, MySQL will be very complicated when selecting indexes, and it is easy to choose the wrong index.
And if there is no hit, the nested loop join is to read a row of data from the two tables for pairwise comparison, and the complexity is n^2.
So we should try to control the number of join tables.
Positive example:
select a.name,b.name.c.name,a.d_name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.idIf you need to query the data in other tables in the implementation of the business scenario, you can redundant special fields in the a, b, and c tables, for example: redundant d_name field in table a to save the data to be queried.
However, I have seen some ERP systems before. The concurrency is not large, but the business is relatively complex. It needs to join more than a dozen tables to query the data.
Therefore, the number of join tables should be determined according to the actual situation of the system. It cannot be generalized. The less the better.
11. Pay attention when joining
We generally use the join keyword when it comes to joint query of multiple tables.
The most commonly used joins are left joins and inner joins.
left join: Find the intersection of two tables plus the remaining data in the left table.inner join: Find the data of the intersection of two tables.
An example of using inner join is as follows:
select o.id,o.code,u.name
from order o
inner join user u on o.user_id = u.id
where u.status=1;If two tables are related using inner join, mysql will automatically select the small table in the two tables to drive the large table, so there will not be too much problem in performance.
An example of using left join is as follows:
select o.id,o.code,u.name
from order o
left join user u on o.user_id = u.id
where u.status=1;If two tables are associated using left join, MySQL will use the left join keyword to drive the table on the right by default. If there is a lot of data in the left table, there will be performance problems.
It should be noted that when using left join to query, use a small table on the left and a large table on the right. If you can use inner join, use left join as little as possible.
12. Control the number of indexes
As we all know, indexes can significantly improve the performance of query SQL, but the number of indexes is not the better.
Because when new data is added to the table, an index needs to be created for it at the same time, and the index requires additional storage space and a certain performance consumption.
Alibaba's developer manual stipulates that the number of indexes in a single table should be controlled within 5 as much as possible, and the number of fields in a single index should not exceed 5.
The structure of the B+ tree used by mysql to save the index, the B+ tree index needs to be updated during insert, update and delete operations. If there are too many indexes, it will consume a lot of extra performance.
So, the question is, what if there are too many indexes in the table, more than 5?
This question needs to be viewed dialectically. If your system has a low concurrency and the amount of data in the table is not much, in fact, more than 5 can be used, as long as it does not exceed too much.
But for some high-concurrency systems, be sure to abide by the limit of no more than 5 indexes on a single table.
So, how does a high concurrency system optimize the number of indexes?
If you can build a joint index, don't build a single index, you can delete a useless single index.
Migrating some query functions to other types of databases, such as Elastic Seach, HBase, etc., only needs to build a few key indexes in the business table.
13. Choose a reasonable field type
char represents a fixed string type. The storage space of the field of this type is fixed, which will waste storage space.
alter table order
add column code char(20) NOT NULL;varchar represents a variable-length string type, and the field storage space of this type will be adjusted according to the length of the actual data, without wasting storage space.
alter table order
add column code varchar(20) NOT NULL;If it is a field with a fixed length, such as the user's mobile phone number, it is generally 11 bits, and can be defined as a char type with a length of 11 bytes.
But if it is an enterprise name field, if it is defined as a char type, there is a problem.
If the length is defined too long, for example, it is defined as 200 bytes, and the actual enterprise length is only 50 bytes, 150 bytes of storage space will be wasted.
If the length is defined too short, for example, it is defined as 50 bytes, but the actual enterprise name has 100 bytes, it will not be stored, and an exception will be thrown.
Therefore, it is recommended to change the enterprise name to varchar type. The storage space of variable-length fields is small, which can save storage space, and for queries, the search efficiency in a relatively small field is obviously higher.
When we choose field types, we should follow these principles:
- If you can use numeric types, you don't need strings, because the processing of characters is often slower than that of numbers.
- Use small types as much as possible, such as: use bit to store boolean values, tinyint to store enumeration values, etc.
- Fixed-length string field, use char type.
- Variable-length string fields, use varchar type.
- Use decimal for the amount field to avoid the problem of loss of precision.
There are many more principles, which are not listed here.
14. Improve the efficiency of group by
We have many business scenarios that need to use the group by keyword, its main function is to deduplicate and group.
Usually it is used in conjunction with having, which means grouping and then filtering data according to certain conditions.
Counter example:
select user_id,user_name from order
group by user_id
having user_id <= 200;This writing method has poor performance. It first groups all orders according to user id, and then filters users whose user id is greater than or equal to 200.
Grouping is a relatively time-consuming operation, why don't we narrow down the data before grouping?
Positive example:
select user_id,user_name from order
where user_id <= 200
group by user_idUse the where condition to filter out the redundant data before grouping, so that the efficiency will be higher when grouping.
In fact, this is an idea, not limited to the optimization of group by. Before our SQL statements do some time-consuming operations, we should reduce the data range as much as possible, which can improve the overall performance of SQL.
15. Index optimization
Among the sql optimization, there is a very important content: index optimization.
In many cases, the execution efficiency of sql statements is very different when the index is used and the index is not used. Therefore, index optimization is the first choice for SQL optimization.
The first step in index optimization is to check whether the sql statement is indexed.
So, how to check whether sql has gone to the index?
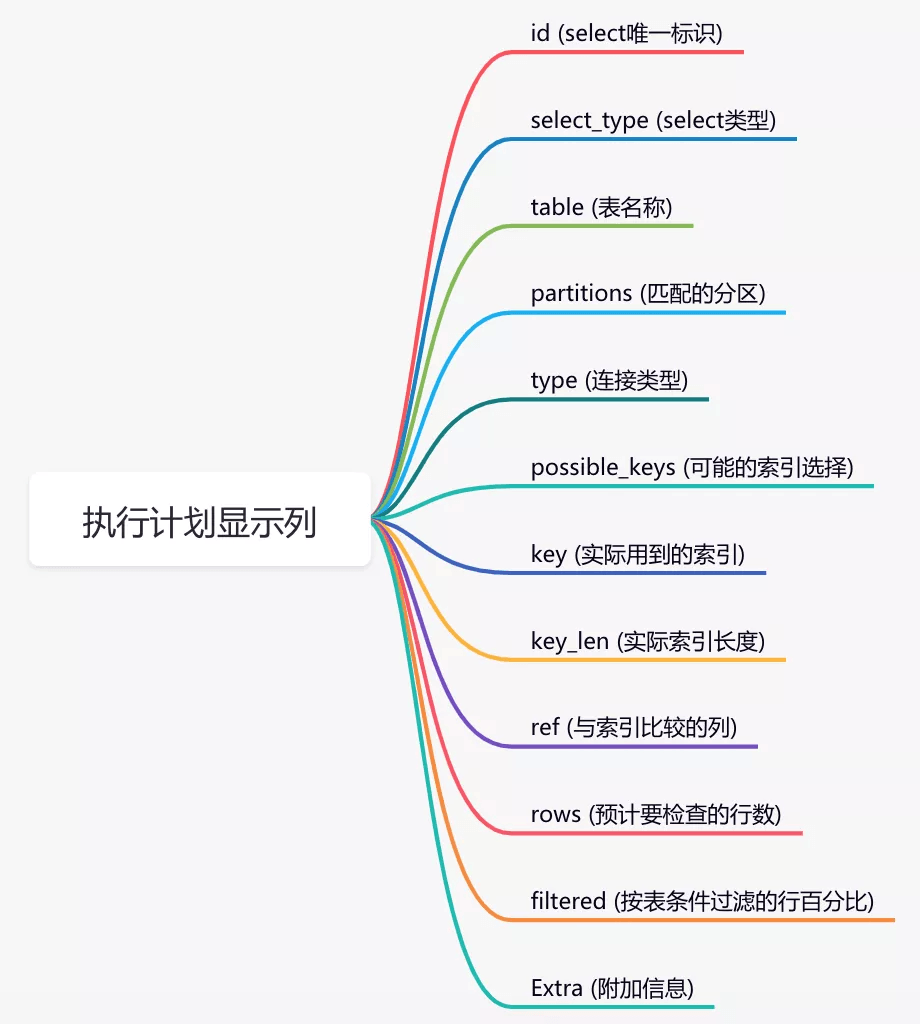
You can use the explain command to view the execution plan of mysql.
E.g:
explain select * from `order` where code='002';result:

The index usage can be judged through these columns. The meaning of the columns included in the execution plan is shown in the following figure:
To be honest, the sql statement does not use the index, except that the index is not built, the biggest possibility is that the index is invalid.
Here are some common reasons for index failure:
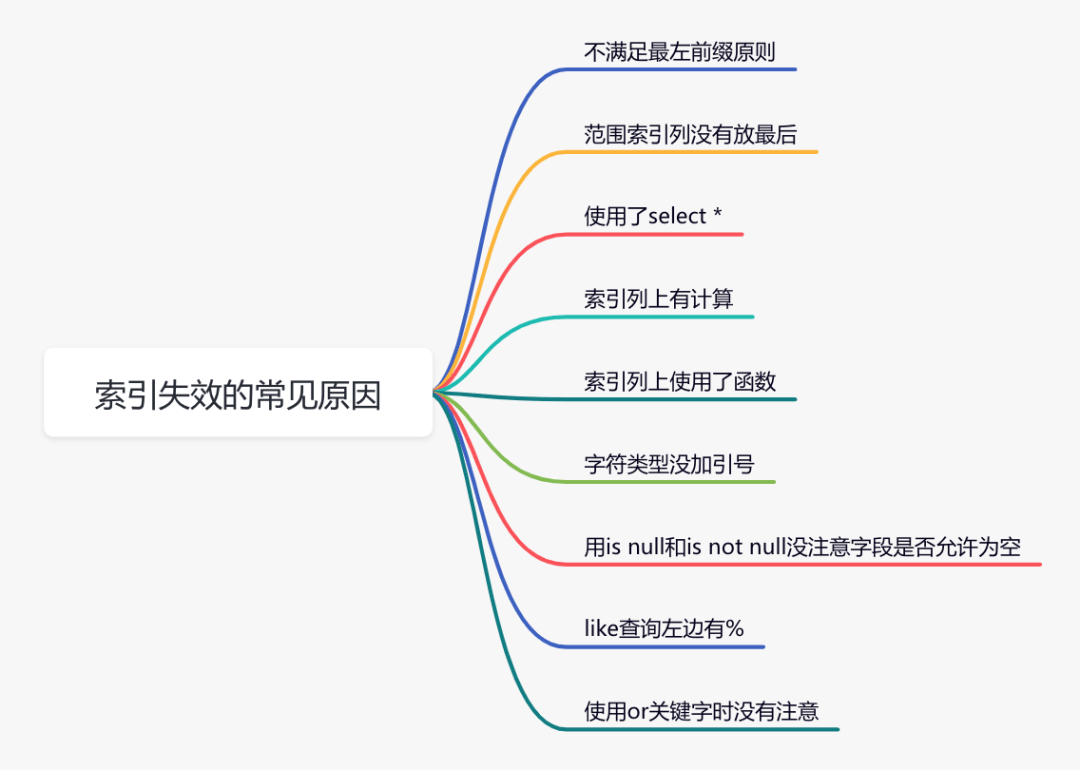
If it is not the above reasons, you need to further investigate other reasons.
In addition, have you ever encountered such a situation: it is obviously the same sql, only the input parameters are different. Sometimes the index a goes, and sometimes the index b?
Yes, sometimes mysql chooses the wrong index.
If necessary, you can use force index to force the query sql to go to a certain index.
Post comment 取消回复