Ever heard of a headless browser? Mainly used for testing purposes, they provide us with an excellent opportunity to crawl websites that require Javascript execution or any other functionality provided by the browser.
You will learn how to use Selenium and its multiple functions to crawl and browse any web page. From finding elements to waiting for dynamic content to load. Modify the window size and take a screenshot. Or add proxies and custom headers to avoid blocking. You can use this headless browser to achieve all these and more features
environment
To make the code work, you need to install python3. Some systems have it pre-installed. After that, install Selenium, Chrome and Chrome drivers. Make sure to match the browser and driver version Chrome 96 at the time of writing
pip install seleniumOther browsers are also available (Edge, IE, Firefox, Opera, Safari), and the code should work with minor adjustments
Example
After the setup is complete, we will write the first test. Go to the example URL and print its current URL and title. The browser will automatically follow the redirection and load all resources-images, style sheets, javascript, etc.
from selenium import webdriver
url = "http://zenrows.com"
with webdriver.Chrome() as driver:
driver.get(url)
print(driver.current_url) # https://www.zenrows.com/
print(driver.title) # Web Scraping API & Data Extraction-ZenRowsIf your Chrome driver is not in the executable path, you need to specify it or move the driver to a location in the path (ie /usr/bin/)
chrome_driver_path ='/path/to/chromedriver'
with webdriver.Chrome(executable_path=chrome_driver_path) as driver:
# ...You noticed that the browser is displaying, you can see it, right? It will not run headless by default. We can pass options to the driver, this is what we are going to do for crawling
options = webdriver.ChromeOptions()
options.headless = True
with webdriver.Chrome(options=options) as driver:
# ...Positioning elements and content
Once the page is loaded, we can start looking for the information we want. Selenium provides multiple methods to access elements: ID, tag name, class, XPath and CSS selector.
Suppose we want to search for something on Amazon using text input. We can use select from the previous option by tag: driver.find_element(By.TAG_NAME, "input"). But this may be a problem because there are multiple inputs on the page. By checking the page, we see that it has an ID, so we changed the selection: driver.find_element(By.ID, "twotabsearchtextbox").
IDs may not change often, and they are a safer way to extract information than classes. The problem usually comes from not being able to find them. Assuming there is no ID, we can select the search form and enter it
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.amazon.com/"
with webdriver.Chrome(options=options) as driver:
driver.get(url)
input = driver.find_element(By.CSS_SELECTOR,
"form[role='search'] input[type='text']")There is no silver bullet; each option applies to a set of cases. You need to find the product that best suits your needs.
If we scroll down the page, we will see many products and categories. There is also a frequently repeated shared class: a-list-item. We need a similar function (plural form of find_elements) to match all items, not just the first occurrence
#...
driver.get(url)
items = driver.find_elements(By.CLASS_NAME, "a-list-item")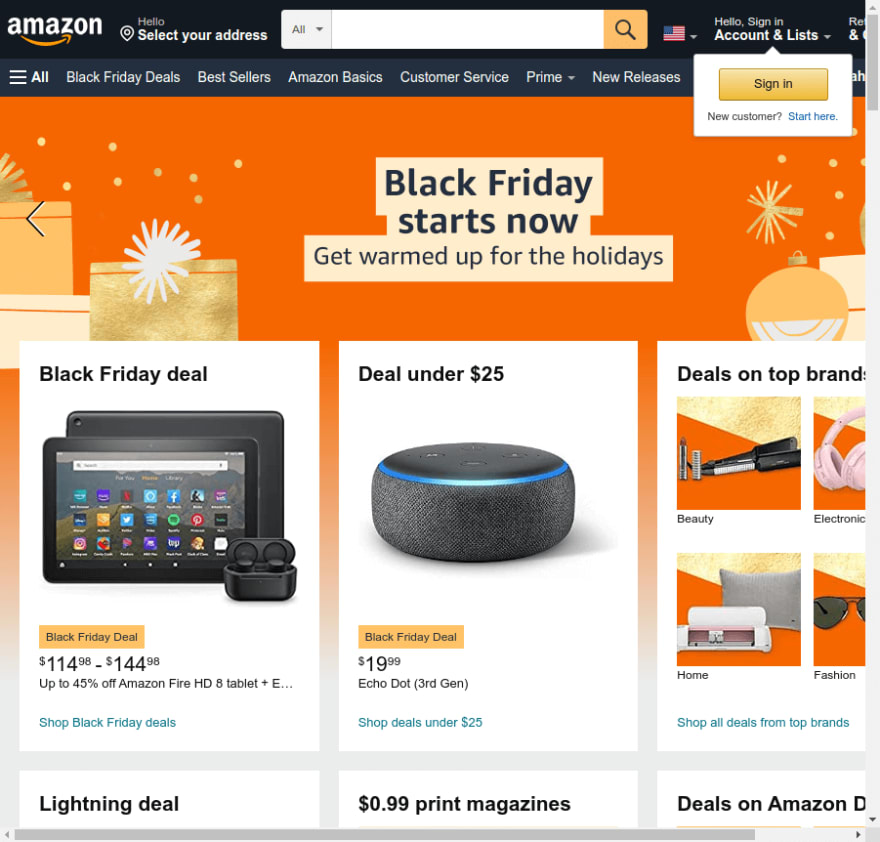
Now we need to do something with the selected element
Interact with elements
We will search using the input selected above. For this, we need send_keys input and press enter to send the form function. We can also enter the input, then find the submit button and click on it (element.click()). It's easier in this case because Enter works fine.
from selenium.webdriver.common.keys import Keys
#...
input = driver.find_element(By.CSS_SELECTOR,
"form[role='search'] input[type='text']")
input.send_keys('Python Books' + Keys.ENTER)Please note that the script does not wait and closes immediately after the search is complete. The logical thing is to do something afterwards, so we will use find_elements to list the results as above. To check the result, we can use the s-result-item class.
We will only select those items whose divs have multiple internal tags. If you are interested, we can get the value of the link and visit each item-we will not do this for the time being. But the h2 tag contains the book title, so we need to select the book title for each element. We can continue to use find_element because it applies to the driver, as mentioned earlier, and any web page element.
# ...
items = driver.find_elements(By.CLASS_NAME, "s-result-item")
for item in items:
h2 = item.find_element(By.TAG_NAME, "h2")
print(h2.text) # Prints a list of around fifty items
# Learning Python, 5th Edition ...Don't rely too much on this method, because some tags may be empty or have no title. We should fully implement error control for actual use cases.
Infinite scroll
For infinite scrolling (Pinterest) or lazy loading of images (Twitter), we can also use the keyboard to browse down. Not often used, but you can choose to use the space bar, "Page Down" or "End" key to scroll. We can take advantage of this.
The driver will not accept it directly. We need to find an element body like this first and send the key there.
driver.find_element(By.TAG_NAME, "body").send_keys(Keys.END)But there is another problem: the item does not appear after scrolling. This brings us to the next part
Waiting for content or element
Many websites today use Javascript-especially when using modern frameworks such as React-and perform a lot of XHR calls after the first load. Like infinite scrolling, Selenium will not be able to use all of this content. But we can manually check the target website and check the result of this processing.
It usually boils down to creating some DOM elements. If these classes are unique or they have IDs, we can wait for them. We can use WebDriverWait to pause the script until certain conditions are met.
Assume a simple situation where there is no image before some XHR is completed. This instruction will return immediately after the img element appears. The driver will wait 3 seconds, otherwise it will fail.
from selenium.webdriver.support.ui import WebDriverWait
# ...
el = WebDriverWait(driver, timeout=3).until(
lambda d: d.find_element(By.TAG_NAME, "img"))Selenium provides several expectations that may prove valuable. element_to_be_clickable is a good example in a page full of Javascript, because many buttons are not interactive until certain operations occur.
from selenium.webdriver.support import expected_conditions as EC
#...
button = WebDriverWait(driver, 3).until(
EC.element_to_be_clickable((By.CLASS_NAME,'my-button')))Screenshots and element screenshots
Whether for testing purposes or storing changes, screenshots are a useful tool. We can take a screenshot of the current browser context or a given element.
# ...
driver.save_screenshot('page.png')
# ...
card = driver.find_element(By.CLASS_NAME, "a-cardui")
card.screenshot("amazon_card.png")
Did you notice the problem with the first picture? There is nothing wrong, but the size may not be what you expect. When browsing in headless mode, Selenium loads 800 pixels x 600 pixels by default. But we can modify it to get a larger screenshot.
Window size
We can query the driver to check the size we are starting: driver.get_window_size(), it will print {'width': 800,'height': 600}. When using the GUI, these numbers will change, so let's assume We are testing headless mode.
There is a similar function-set_window_size-which will modify the window size. Or we can add an option parameter to the Chrome web driver, and it will directly launch the browser at that resolution.
options.add_argument("--window-size=1024,768")
with webdriver.Chrome(options=options) as driver:
print(driver.get_window_size())
# {'width': 1024,'height': 768}
driver.set_window_size(1920,1200)
driver.get(url)
print(driver.get_window_size())
# {'width': 1920,'height': 1200}Now our screenshot will be 1920px wide

Custom Title
The options mentioned above provide us with an important web crawling mechanism: custom title.
User Agent
One of the basic header files to avoid blocking is User-Agent. By default, Selenium will provide an accurate one, but you can change it to a custom one. Keep in mind that there are many techniques for crawling and scraping without blocks, we won't cover them all here.
user_agent ='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
options.add_argument('user-agent=%s'% user_agent)
with webdriver.Chrome(options=options) as driver:
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text) # UA matches the one hardcoded above, v93Other important titles
As a quick summary, if we forget to adjust some other titles, changing the user agent may backfire. For example, the sec-ch-ua header usually sends a version of the browser, which must match the version of the user agent: "Google Chrome";v="96". But some older versions do not send this header at all, so sending it may also be suspicious.
The problem is that Selenium does not support adding headers. A third-party solution like Selenium Wire may solve it. Install it pip install selenium-wire.
It will allow us to intercept requests etc. and modify the headers we want or add new headers. When making changes, be sure to delete the original ones first to avoid repetitions.
from seleniumwire import webdriver
url = "http://httpbin.org/anything"
user_agent ='Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
sec_ch_ua ='"Google Chrome";v="93", "Not;A Brand";v="99", "Chromium";v="93"'
referer ='https://www.google.com'
options = webdriver.ChromeOptions()
options.headless = True
def interceptor(request):
del request.headers['user-agent'] # Delete the header first
request.headers['user-agent'] = user_agent
request.headers['sec-ch-ua'] = sec_ch_ua
request.headers['referer'] = referer
with webdriver.Chrome(options=options) as driver:
driver.request_interceptor = interceptor
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text)Proxy change IP
Like headers, Selenium has limited support for proxies. We can add a proxy without authentication as a driver option. For testing, we will use free agents, although they are not reliable, and the following may not be suitable for you at all. They are usually short-lived.
from selenium import webdriver
# ...
url = "http://httpbin.org/ip"
proxy = '85.159.48.170:40014' # free proxy
options.add_argument('--proxy-server=%s'% proxy)
with webdriver.Chrome(options=options) as driver:
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text) # "origin": "85.159.48.170"For more complex solutions or solutions that require authentication, Selenium Wire can help us again. In this case, we need a second set of options where we will add the proxy server to be used.
proxy_pass = "YOUR_API_KEY"
seleniumwire_options = {
'proxy': {
"http": f"http://{proxy_pass}:@proxy.zenrows.com:8001",
'verify_ssl': False,
},
}
with webdriver.Chrome(options=options,
seleniumwire_options=seleniumwire_options) as driver:
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text)For proxy servers that do not automatically rotate IP, driver.proxy can be overwritten. From then on, all requests will use the new proxy. You can do this as many times as you need. For convenience and reliability, we advocate the use of intelligent rotating agents.
#...
driver.get(url) # Initial proxy
driver.proxy = {
'http':'http://user:pass@1.2.3.4:5678',
}
driver.get(url) # New proxyBlocking resources
For performance, saving bandwidth, or avoiding tracking, blocking certain resources when scaling crawls may be critical.
from selenium import webdriver
url = "https://www.amazon.com/"
options = webdriver.ChromeOptions()
options.headless = True
options.experimental_options["prefs"] = {
"profile.managed_default_content_settings.images": 2
}
with webdriver.Chrome(options=options) as driver:
driver.get(url)
driver.save_screenshot('amazon_without_images.png'){{image.png(uploading...)}}
We can even go one step further and avoid loading almost any type. Be careful with this, because blocking Javascript means no AJAX calls, for example.
options.experimental_options["prefs"] = {
"profile.managed_default_content_settings.images": 2,
"profile.managed_default_content_settings.stylesheets": 2,
"profile.managed_default_content_settings.javascript": 2,
"profile.managed_default_content_settings.cookies": 2,
"profile.managed_default_content_settings.geolocation": 2,
"profile.default_content_setting_values.notifications": 2,
}Intercept request
Once again, thanks to Selenium Wire, we can decide the request programmatically. This means that we can effectively block certain images while allowing others. We can also exclude_hosts based on URLs matching regular expressions to block domain usage or only allow specific requests driver.scopes
def interceptor(request):
# Block PNG and GIF images, will show JPEG for example
if request.path.endswith(('.png','.gif')):
request.abort()
with webdriver.Chrome(options=options) as driver:
driver.request_interceptor = interceptor
driver.get(url)Execute Javascript
The last Selenium feature we want to mention is the execution of Javascript. Some things are easier to do directly in the browser, or we want to check if it is working properly. We can execute_script to pass the JS code we want to execute. It can take no parameters or use elements as parameters.
We can see both cases in the example below. When the browser sees it, no parameters are needed to get the user agent. This may help to check whether the sent navigator object is correctly modified in the object, otherwise certain safety checks may trigger red flags. The second one takes ah2 as a parameter and returns its left position by accessing getClientRects.
with webdriver.Chrome(options=options) as driver:
driver.get(url)
agent = driver.execute_script("return navigator.userAgent")
print(agent) # Mozilla/5.0 ... Chrome/96 ...
header = driver.find_element(By.CSS_SELECTOR, "h2")
headerText = driver.execute_script(
'return arguments[0].getClientRects()[0].left', header)
print(headerText) # 242.5Selenium is a valuable tool with many applications, but you must use them in your own way. Apply every feature that is beneficial to you. Many times, there are several ways to get to the same point; look for the one that can help you best-or the simplest
Once you have the handle, you will want to increase your crawl volume and get more pages. Other challenges may arise: large-scale crawling and blocking. Some of the tips above will help you: check the title and proxy section. But please also note that large-scale crawling is not easy

Post comment 取消回复