听说过无头浏览器吗?主要用于测试目的,它们为我们提供了一个极好的机会来抓取需要 Javascript 执行或浏览器提供的任何其他功能的网站。
您将学习如何使用Selenium及其多种功能来抓取和浏览任何网页。从查找元素到等待动态内容加载。修改窗口大小并截屏。或者添加代理和自定义标头以避免阻塞。您可以使用这款无头浏览器实现所有这些以及更多功能
环境
要使代码正常工作,您需要安装 python3。有些系统已经预先安装了它。之后,安装 Selenium、Chrome和Chrome驱动程序。确保在撰写本文时匹配浏览器和驱动程序版本 Chrome 96
pip install selenium 其他浏览器也可用(Edge、IE、Firefox、Opera、Safari),并且代码应该在稍作调整后工作
示例
设置完成后,我们将编写第一个测试。转到示例 URL 并打印其当前 URL 和标题。浏览器将自动跟随重定向并加载所有资源 - 图像、样式表、javascript 等
from selenium import webdriver
url = "http://zenrows.com"
with webdriver.Chrome() as driver:
driver.get(url)
print(driver.current_url) # https://www.zenrows.com/
print(driver.title) # Web Scraping API & Data Extraction - ZenRows如果您的 Chrome 驱动程序不在可执行路径中,您需要指定它或将驱动程序移动到路径中的某个位置(即/usr/bin/)
chrome_driver_path = '/path/to/chromedriver'
with webdriver.Chrome(executable_path=chrome_driver_path) as driver:
# ...您注意到浏览器正在显示,您可以看到它,对吗?默认情况下它不会无头运行。我们可以将选项传递给驱动程序,这就是我们要为抓取做的事情
options = webdriver.ChromeOptions()
options.headless = True
with webdriver.Chrome(options=options) as driver:
# ...定位元素和内容
一旦页面加载完毕,我们就可以开始寻找我们想要的信息了。Selenium 提供了多种访问元素的方法:ID、标签名称、类、XPath 和 CSS 选择器。
假设我们想使用文本输入在 Amazon 上搜索某些内容。我们可以使用select按标签从以前的选项:driver.find_element(By.TAG_NAME, "input")。但这可能是一个问题,因为页面上有多个输入。通过检查页面,我们看到它有一个ID,所以我们改变了选择:driver.find_element(By.ID, "twotabsearchtextbox")。
ID 可能不会经常更改,并且它们是一种比类更安全的信息提取方式。问题通常来自找不到它们。假设没有ID,我们可以选择搜索表单,然后在里面输入
from selenium import webdriver
from selenium.webdriver.common.by import By
url = "https://www.amazon.com/"
with webdriver.Chrome(options=options) as driver:
driver.get(url)
input = driver.find_element(By.CSS_SELECTOR,
"form[role='search'] input[type='text']")没有银弹;每个选项都适用于一组案例。您需要找到最适合您需求的产品。
如果我们向下滚动页面,我们会看到许多产品和类别。还有一个经常重复的共享类:a-list-item. 我们需要一个类似的函数(find_elements复数形式)来匹配所有项目,而不仅仅是第一次出现
#...
driver.get(url)
items = driver.find_elements(By.CLASS_NAME, "a-list-item")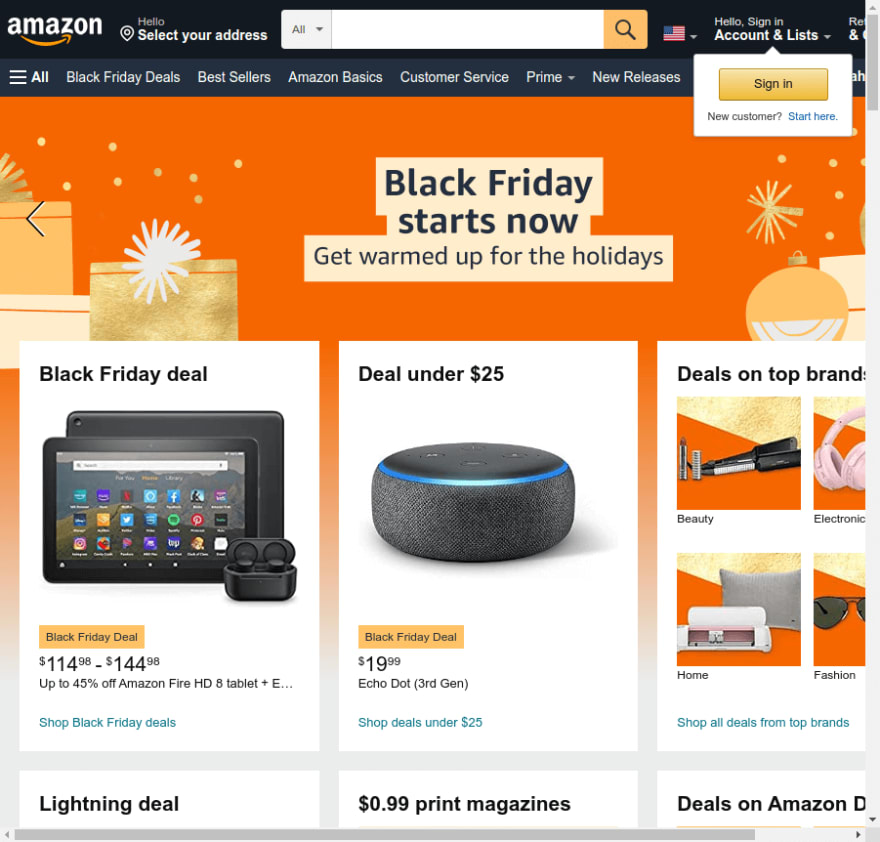
现在我们需要对选定的元素做一些事情
与元素互动
我们将使用上面选择的输入进行搜索。为此,我们需要send_keys输入并按回车键发送表单的函数。我们也可以输入输入,然后找到提交按钮并单击它(element.click())。在这种情况下更容易,因为Enter工作正常。
from selenium.webdriver.common.keys import Keys
#...
input = driver.find_element(By.CSS_SELECTOR,
"form[role='search'] input[type='text']")
input.send_keys('Python Books' + Keys.ENTER)请注意,该脚本不会等待并在搜索完成后立即关闭。合乎逻辑的事情是在之后做一些事情,所以我们将使用find_elements如上列出结果。检查结果,我们可以使用s-result-item该类。
我们将只选择div带有多个内部标签的这些项目。href如果有兴趣,我们可以获取链接的值并访问每个项目 - 我们暂时不会这样做。但是h2标签包含书名,所以我们需要为每个元素选择书名。我们可以继续使用,find_element因为它适用于driver,如前所述,以及任何网页元素。
# ...
items = driver.find_elements(By.CLASS_NAME, "s-result-item")
for item in items:
h2 = item.find_element(By.TAG_NAME, "h2")
print(h2.text) # Prints a list of around fifty items
# Learning Python, 5th Edition ...不要过分依赖这种方法,因为有些标签可能是空的或没有标题。我们应该为实际用例充分实施错误控制。
无限滚动
对于无限滚动 (Pinterest) 或延迟加载图像 (Twitter) 的情况,我们也可以使用键盘向下浏览。不经常使用,但可以选择使用空格键、“Page Down”或“End”键滚动。我们可以利用这一点。
司机不会直接接受。我们需要先找到一个像这样的元素body并将密钥发送到那里。
driver.find_element(By.TAG_NAME, "body").send_keys(Keys.END)但还有另一个问题:滚动后项目不会出现。这将我们带到下一部分
等待内容或元素
如今,许多网站都使用 Javascript - 特别是在使用 React 等现代框架时 - 并且在第一次加载后执行大量 XHR 调用。与无限滚动一样,Selenium 将无法使用所有这些内容。但是我们可以手动检查目标网站并检查该处理的结果。
它通常归结为创建一些 DOM 元素。如果这些类是唯一的或者它们有 ID,我们可以等待它们。我们可以使用WebDriverWait来暂停脚本,直到满足某些条件。
假设一个简单的情况,在某些 XHR 完成之前不存在图像。该指令将在img元素出现后立即返回。驱动程序将等待 3 秒,否则将失败。
from selenium.webdriver.support.ui import WebDriverWait
# ...
el = WebDriverWait(driver, timeout=3).until(
lambda d: d.find_element(By.TAG_NAME, "img"))Selenium 提供了几个可能证明有价值的预期条件。element_to_be_clickable在充满 Javascript 的页面中是一个很好的例子,因为许多按钮在某些操作发生之前是不可交互的。
from selenium.webdriver.support import expected_conditions as EC
#...
button = WebDriverWait(driver, 3).until(
EC.element_to_be_clickable((By.CLASS_NAME, 'my-button')))截图和元素截图
无论是出于测试目的还是存储更改,屏幕截图都是一种实用的工具。我们可以为当前浏览器上下文或给定元素截取屏幕截图。
# ...
driver.save_screenshot('page.png')
# ...
card = driver.find_element(By.CLASS_NAME, "a-cardui")
card.screenshot("amazon_card.png")
注意到第一张图片的问题了吗?没有错,但大小可能不是您所期望的。在无头模式下浏览时,Selenium 默认加载 800 像素 x 600 像素。但是我们可以修改它以获取更大的屏幕截图。
窗口大小
我们可以查询驱动程序以检查我们正在启动的大小:driver.get_window_size(),它将打印{'width': 800, 'height': 600}. 使用 GUI 时,这些数字会发生变化,所以让我们假设我们正在测试无头模式。
有一个类似的功能 - set_window_size- 将修改窗口大小。或者我们可以向 Chrome 网络驱动程序添加一个选项参数,它将直接以该分辨率启动浏览器。
options.add_argument("--window-size=1024,768")
with webdriver.Chrome(options=options) as driver:
print(driver.get_window_size())
# {'width': 1024, 'height': 768}
driver.set_window_size(1920,1200)
driver.get(url)
print(driver.get_window_size())
# {'width': 1920, 'height': 1200}现在我们的屏幕截图将是 1920px 宽

自定义标题
上面提到的选项为我们提供了一个重要的网页抓取机制:自定义标题。
用户代理
避免阻塞的基本头文件之一是 User-Agent。默认情况下,Selenium 将提供一个准确的,但您可以将其更改为自定义的。请记住,有许多技术可以在没有块的情况下进行爬行和抓取,我们不会在此处全部介绍。
user_agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
options.add_argument('user-agent=%s' % user_agent)
with webdriver.Chrome(options=options) as driver:
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text) # UA matches the one hardcoded above, v93其他重要标题
作为一个快速总结,如果我们忘记调整一些其他标题,更改用户代理可能会适得其反。例如,sec-ch-ua标头通常发送浏览器的一个版本,它必须与用户代理的版本一致:"Google Chrome";v="96"。但是一些旧版本根本不发送该标头,因此发送它也可能是可疑的。
问题是 Selenium 不支持添加标头。像Selenium Wire这样的第三方解决方案可能会解决它。安装它pip install selenium-wire。
它将允许我们拦截请求等,并修改我们想要的标头或添加新标头。改的时候一定要先把原来的删掉,以免发重复。
from seleniumwire import webdriver
url = "http://httpbin.org/anything"
user_agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
sec_ch_ua = '"Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"'
referer = 'https://www.google.com'
options = webdriver.ChromeOptions()
options.headless = True
def interceptor(request):
del request.headers['user-agent'] # Delete the header first
request.headers['user-agent'] = user_agent
request.headers['sec-ch-ua'] = sec_ch_ua
request.headers['referer'] = referer
with webdriver.Chrome(options=options) as driver:
driver.request_interceptor = interceptor
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text)代理更改IP
与标头一样,Selenium 对代理的支持有限。我们可以添加一个无需身份验证的代理作为驱动程序选项。对于测试,我们将使用免费代理,尽管它们不可靠,而且下面的可能根本不适合您。它们通常是短暂的。
from selenium import webdriver
# ...
url = "http://httpbin.org/ip"
proxy = '85.159.48.170:40014' # free proxy
options.add_argument('--proxy-server=%s' % proxy)
with webdriver.Chrome(options=options) as driver:
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text) # "origin": "85.159.48.170"对于更复杂的解决方案或需要身份验证的解决方案,Selenium Wire 可以再次帮助我们。在这种情况下,我们需要第二组选项,我们将在其中添加要使用的代理服务器。
proxy_pass = "YOUR_API_KEY"
seleniumwire_options = {
'proxy': {
"http": f"http://{proxy_pass}:@proxy.zenrows.com:8001",
'verify_ssl': False,
},
}
with webdriver.Chrome(options=options,
seleniumwire_options=seleniumwire_options) as driver:
driver.get(url)
print(driver.find_element(By.TAG_NAME, "body").text)对于不自动轮换 IP 的代理服务器,driver.proxy可以被覆盖。从那时起,所有请求都将使用新代理。可以根据需要多次执行此操作。为了方便和可靠,我们提倡使用智能旋转代理。
#...
driver.get(url) # Initial proxy
driver.proxy = {
'http': 'http://user:pass@1.2.3.4:5678',
}
driver.get(url) # New proxy阻塞资源
对于性能、节省带宽或避免跟踪,在扩展抓取时阻止某些资源可能是至关重要的。
from selenium import webdriver
url = "https://www.amazon.com/"
options = webdriver.ChromeOptions()
options.headless = True
options.experimental_options["prefs"] = {
"profile.managed_default_content_settings.images": 2
}
with webdriver.Chrome(options=options) as driver:
driver.get(url)
driver.save_screenshot('amazon_without_images.png'){{image.png(uploading...)}}
我们甚至可以更进一步,避免加载几乎任何类型。小心这一点,因为阻塞 Javascript 意味着没有 AJAX 调用,例如。
options.experimental_options["prefs"] = {
"profile.managed_default_content_settings.images": 2,
"profile.managed_default_content_settings.stylesheets": 2,
"profile.managed_default_content_settings.javascript": 2,
"profile.managed_default_content_settings.cookies": 2,
"profile.managed_default_content_settings.geolocation": 2,
"profile.default_content_setting_values.notifications": 2,
}拦截请求
再一次,感谢 Selenium Wire,我们可以以编程方式决定请求。这意味着我们可以有效地阻止某些图像同时允许其他图像。我们还可以exclude_hosts根据与正则表达式匹配的 URL来阻止域使用或仅允许特定请求driver.scopes
def interceptor(request):
# Block PNG and GIF images, will show JPEG for example
if request.path.endswith(('.png', '.gif')):
request.abort()
with webdriver.Chrome(options=options) as driver:
driver.request_interceptor = interceptor
driver.get(url)执行Javascript
我们要提到的最后一个 Selenium 特性是执行 Javascript。有些事情直接在浏览器中更容易完成,或者我们想检查它是否正常工作。我们可以execute_script传递我们想要执行的JS代码。它可以不带参数或使用元素作为参数。
我们可以在下面的示例中看到这两种情况。当浏览器看到它时,不需要参数来获取用户代理。这可能有助于检查发送的navigator对象是否在对象中被正确修改,否则某些安全检查可能会引发危险信号。第二个将 ah2作为参数并通过访问返回其左侧位置getClientRects。
with webdriver.Chrome(options=options) as driver:
driver.get(url)
agent = driver.execute_script("return navigator.userAgent")
print(agent) # Mozilla/5.0 ... Chrome/96 ...
header = driver.find_element(By.CSS_SELECTOR, "h2")
headerText = driver.execute_script(
'return arguments[0].getClientRects()[0].left', header)
print(headerText) # 242.5Selenium 是具有许多应用程序的宝贵工具,但您必须以自己的方式利用它们。应用对您有利的每个功能。很多时候,有几种方法可以到达同一点;寻找最能帮助你的——或者最简单的
一旦掌握了句柄,您就会想要增加抓取量并获得更多页面。其他挑战可能会出现:大规模爬行和阻塞。上面的一些提示将帮助您:检查标题和代理部分。但也请注意,大规模爬行并非易事

发表评论 取消回复